功能富集分析
从差异基因到生物学解释
王诗翔 副教授
中南大学生物医学信息系
中南大学生物医学信息系
2026-04-30
课程大纲
本讲内容
- 为什么需要功能富集分析
- 功能注释数据库
- 基因ID转换
- 过表达分析(ORA)
- KEGG通路富集
- GSEA简介
- 结果可视化
- 结果解读与报告
第1部分:为什么需要功能富集分析
1.1 问题背景
差异表达分析后,你可能得到:
上调基因:1,500个
下调基因:1,200个面对数千个基因,如何理解其生物学意义?
分析目标
| 目标 | 说明 |
|---|---|
| 降维 | 从基因列表到功能类别 |
| 解释 | 识别受影响的生物学过程 |
| 假设生成 | 发现新的研究方向 |
1.2 分析流程
差异基因列表 → 功能富集分析 → 生物学洞察
┌──────────┐ ┌──────────┐ ┌──────────┐
│ Gene A │ │ GO:1234 │ │ 细胞增殖 │
│ Gene B │ → │ KEGG:567 │ → │ 信号通路 │
│ Gene C │ │ GO:5678 │ │ 代谢过程 │
│ ... │ │ ... │ │ ... │
└──────────┘ └──────────┘ └──────────┘第2部分:功能注释数据库
2.1 Gene Ontology (GO)
三大分支:
| 分支 | 缩写 | 描述 | 示例 |
|---|---|---|---|
| 细胞组分 | CC | 基因产物所在位置 | nucleus, membrane |
| 分子功能 | MF | 基因产物的生化活性 | kinase activity |
| 生物过程 | BP | 参与的生物学过程 | cell division |
GO结构:有向无环图(DAG)
生物过程 (Biological Process)
│
┌─────────┴─────────┐
│ │
细胞增殖 细胞凋亡
│
┌────┴────┐
│ │
DNA复制 有丝分裂2.2 KEGG通路
| 数据库 | 内容 | 应用 |
|---|---|---|
| PATHWAY | 代谢通路、信号通路 | 通路富集分析 |
| GENES | 基因序列信息 | 基因注释 |
| DISEASE | 疾病相关基因 | 疾病研究 |
常见KEGG通路
- 代谢通路:糖酵解、脂肪酸代谢
- 信号通路:MAPK、PI3K-Akt、Wnt
- 疾病通路:Pathways in cancer
- 免疫通路:T细胞受体、B细胞受体
第3部分:基因ID转换
3.1 为什么需要ID转换?
不同数据库使用不同的基因标识符:
| ID类型 | 示例 | 使用场景 |
|---|---|---|
| SYMBOL | TP53, BRCA1 | 人类可读 |
| ENTREZID | 7157, 672 | NCBI数据库 |
| ENSEMBL | ENSG00000141510 | Ensembl数据库 |
| UNIPROT | P04637 | 蛋白数据库 |
| KEGG | hsa:7157 | KEGG通路 |
3.2 clusterProfiler进行ID转换
警告
注意:ID转换可能不完全,部分基因可能没有对应的目标ID
第4部分:过表达分析(ORA)
4.1 ORA原理
核心问题:某GO/通路中的差异基因是否比随机期望更多?
超几何检验:
背景基因:N个(如20,000,所有检测到的基因)
背景中属于某通路的基因:M个
差异基因:n个
差异基因中属于该通路的基因:k个
P(X=k) = C(M,k) × C(N-M, n-k) / C(N,n)4.1 ORA原理
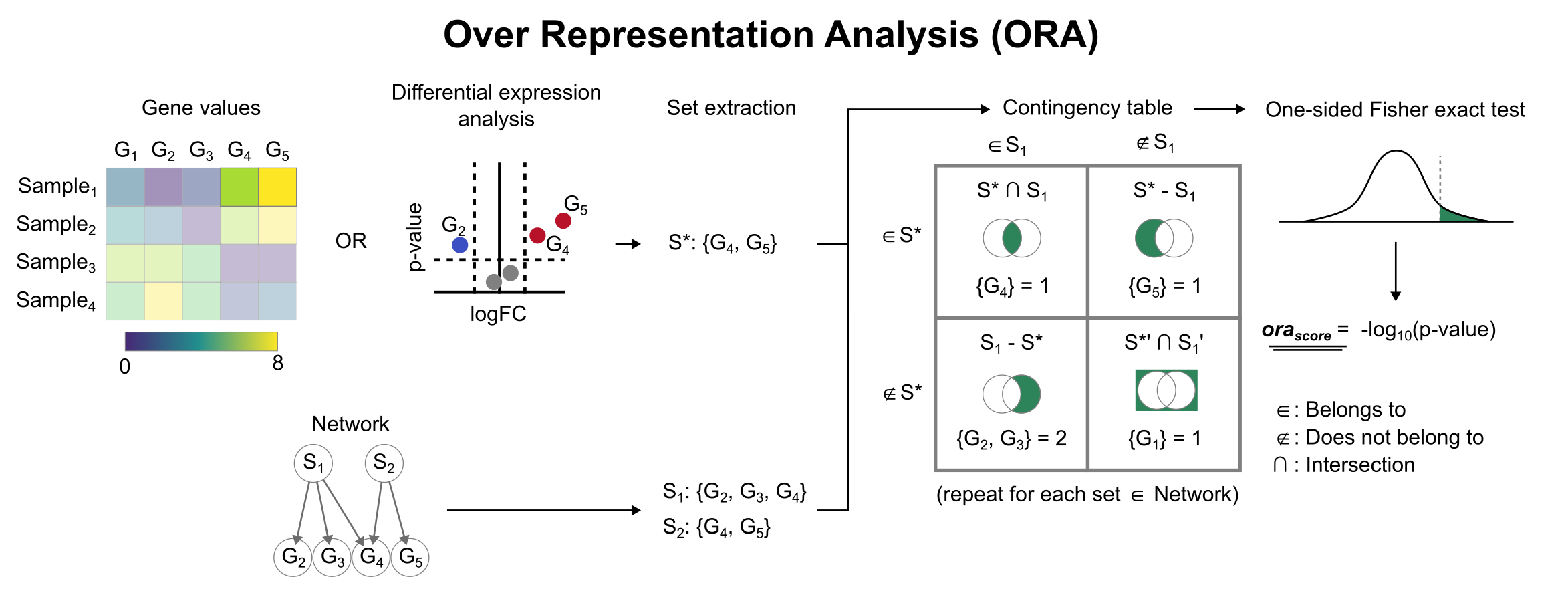
4.2 ORA分析步骤
1. 获取差异基因列表(|log2FC|>1, padj<0.05)
↓
2. 选择背景基因集(所有检测到的基因)
↓
3. 基因ID转换(如SYMBOL → ENTREZID)
↓
4. 对每个GO/通路进行超几何检验
↓
5. 多重检验校正(BH)
↓
6. 筛选显著富集的条目(p.adjust < 0.05)4.3 GO富集分析代码
4.4 ORA结果解读
| 列名 | 含义 | 说明 |
|---|---|---|
| ID | GO/通路ID | 唯一标识符 |
| Description | 描述 | 功能名称 |
| GeneRatio | k/n | 差异基因中属于该通路的比率 |
| BgRatio | M/N | 背景中属于该通路的比率 |
| pvalue | 原始p值 | 富集显著性 |
| p.adjust | 校正p值 | BH校正后 |
| Count | k | 属于该通路的差异基因数 |
第5部分:KEGG通路富集
5.1 KEGG分析的特殊性
注意:enrichKEGG() 支持的ID类型与GO不同:
- 支持:kegg, ncbi-geneid, ncbi-proteinid, uniprot
- 不支持:SYMBOL, ENSEMBL
常用物种代码
| 物种 | 代码 | 说明 |
|---|---|---|
| 人类 | hsa | Homo sapiens |
| 小鼠 | mmu | Mus musculus |
| 大鼠 | rno | Rattus norvegicus |
5.2 KEGG分析代码
警告
常见问题:KEGG数据库在国外,可能被防火墙阻挡
第6部分:GSEA简介
6.1 ORA的局限性
- 需要预设阈值筛选差异基因(丢失阈值附近的基因)
- 丢失微小但协调变化的基因
- 忽略基因表达变化的方向
6.2 GSEA原理
Gene Set Enrichment Analysis:
- 根据所有基因排序(如log2FC从高到低)
- 评估基因集成员是否富集在排序列表顶部或底部
- 计算富集分数(Enrichment Score, ES)
排序的基因列表(按log2FC从高到低):
log2FC: +5 +3 +1 0 -1 -3 -5
│ │ │ │ │ │ │
Gene: A───B───C───D───E───F───G───H───I───J
↑ ↑ ↑
通路X成员 通路Y成员6.3 GSEA分析代码
6.4 ORA vs GSEA
| 特性 | ORA | GSEA |
|---|---|---|
| 输入 | 差异基因列表 | 全部基因(排序) |
| 阈值依赖 | 是 | 否 |
| 检测微弱信号 | 弱 | 强 |
| 计算量 | 小 | 大 |
| 适用场景 | 快速筛选 | 深入分析 |
第7部分:结果可视化
7.1 条形图和点图
条形图
点图(推荐)
点图解读:
- 点大小:富集基因数(Count)
- 颜色:显著性(p.adjust)
- X轴:GeneRatio
7.2 网络图(Cnetplot)
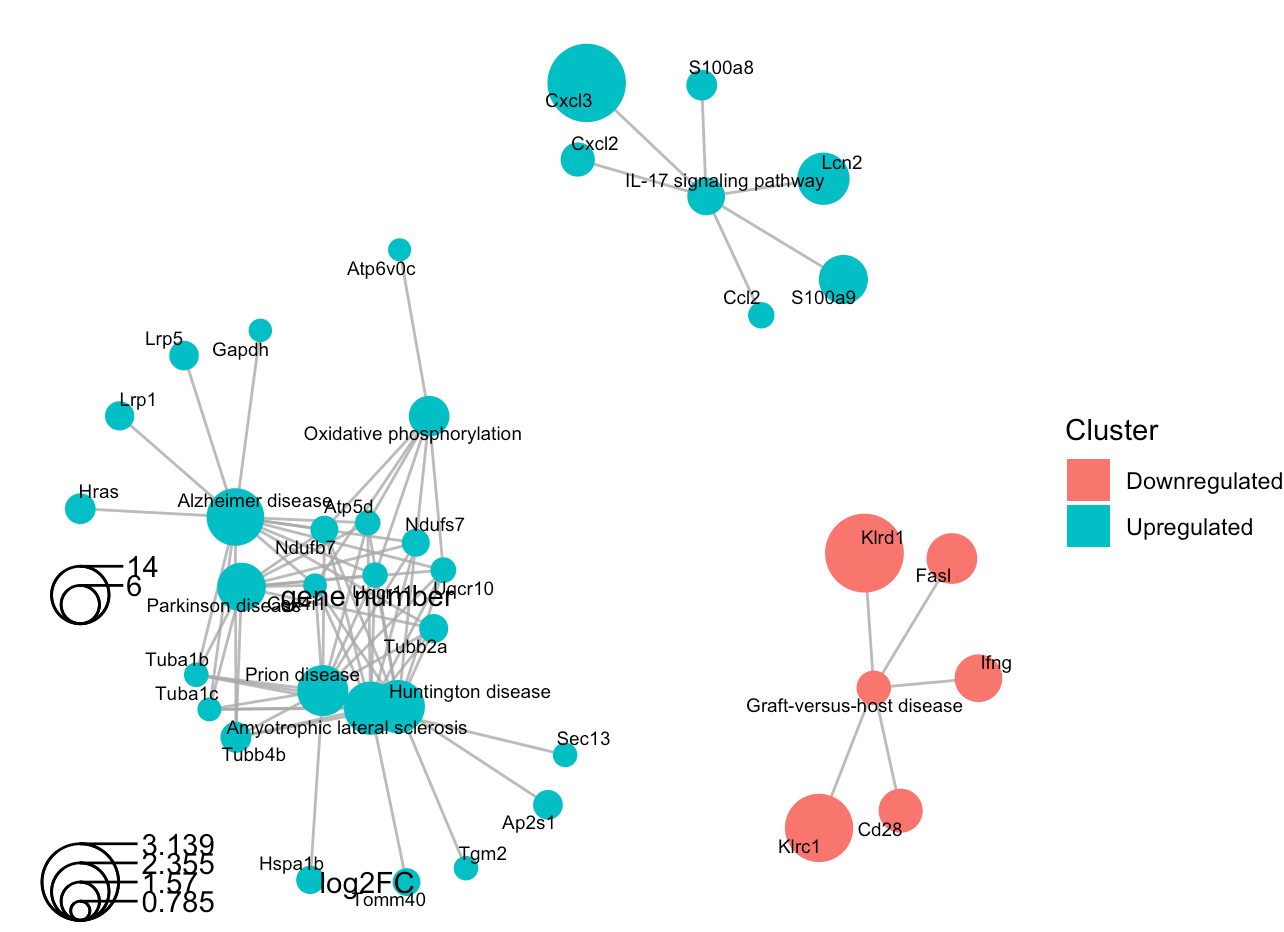
用途:
- 显示富集条目间的基因重叠
- 查看哪些基因参与多个通路
7.3 GSEA Mountain Plot
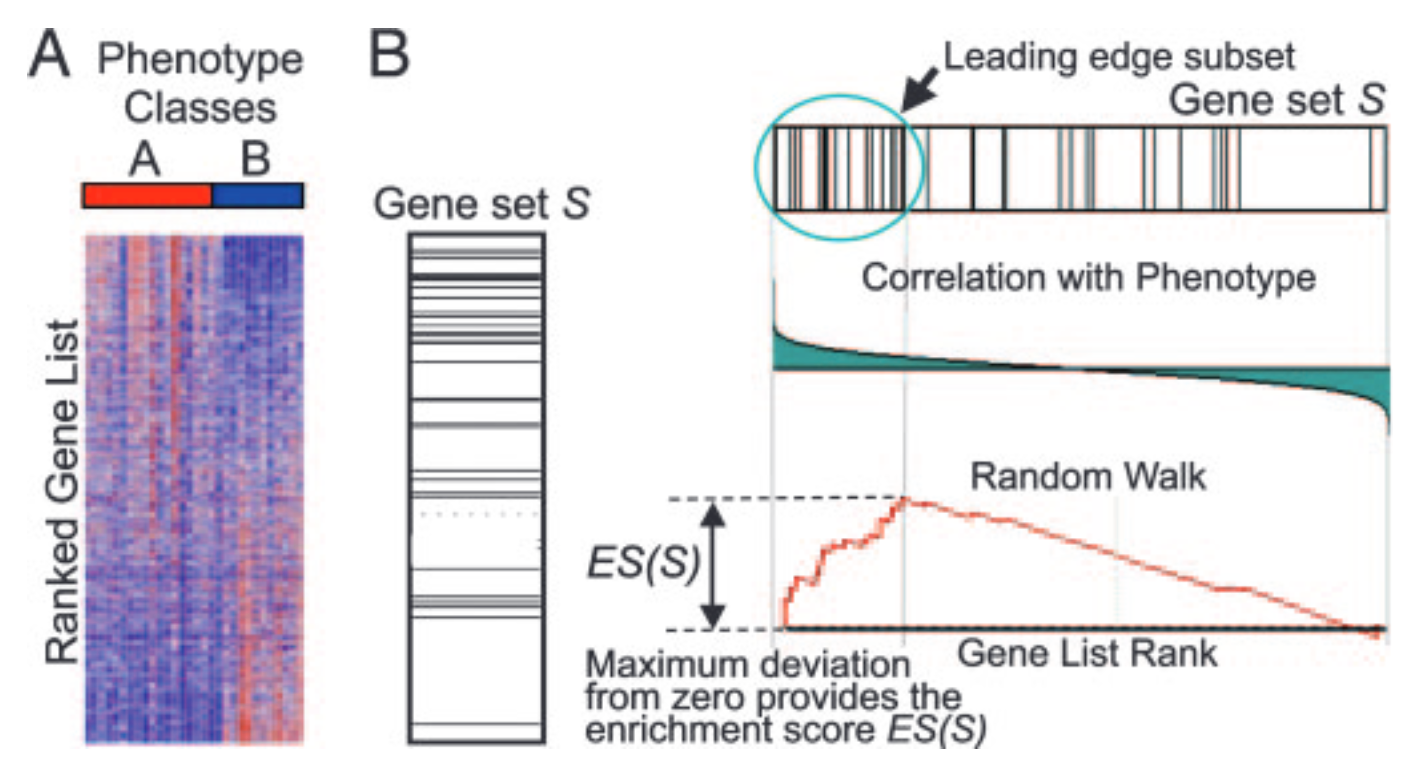
解读:
- 富集分数曲线
- 黑色竖线:基因集中基因在排序列表中的位置
- 热图:基因表达值分布
第8部分:结果解读与报告
8.1 撰写富集分析结果
示例描述:
8.2 注意事项
| 注意事项 | 说明 |
|---|---|
| 选择合适背景 | 使用所有检测到的基因作为背景,而非全基因组 |
| 关注GeneRatio | 高富集比(>2)更可靠 |
| 结合表达方向 | 上调和下调基因分别富集分析 |
| 避免过度解读 | 富集≠因果,需实验验证 |
| 文献验证 | 关键通路需结合已有文献支持 |
8.3 常见问题排查
| 问题 | 可能原因 | 解决方案 |
|---|---|---|
| 富集结果为空 | ID转换失败 | 检查keyType是否正确 |
| 阈值过严 | 放宽pvalueCutoff | |
| 结果过多 | 阈值过松 | 使用qvalue或更严格的p.adjust |
| 通路名称不显示 | 网络问题 | 检查KEGG数据库连接 |
总结
功能富集分析要点
- 功能数据库 — GO(CC/MF/BP)、KEGG是主要资源
- ID转换 — 使用
bitr()进行SYMBOL↔︎ENTREZID转换 - ORA原理 — 超几何检验评估基因集是否过度代表
- GSEA优势 — 不依赖阈值,可检测协调的微小变化
- 可视化 — 条形图、点图、cnetplot、GSEA mountain plot
- 结果解读 — 关注显著性、GeneRatio、生物学意义
作业
- 以 batch 为协变量完成 ATC vs PTV 的差异表达分析
- 对差异基因进行GO和KEGG富集分析,撰写结果描述
- 使用点图和cnetplot可视化富集结果
- 展示Top1的GSEA结果,并解读其生物学意义
- 主要形式为
.R/.Rmd/Qmd脚本,需包含注释和结果输出
谢谢!
联系方式
- 📧 wangshx@csu.edu.cn
- 🌐 https://wanglabcsu.github.io/
- 🐙 https://github.com/WangLabCSU
延伸阅读
- Yu G, et al. clusterProfiler: an R package for comparing biological themes among gene clusters. OMICS. 2012
- Subramanian A, et al. Gene set enrichment analysis: a knowledge-based approach for interpreting genome-wide expression profiles. PNAS. 2005
- Yu G, et al. clusterProfiler 4.0: A universal enrichment tool for interpreting omics data. Innovation. 2021
![]()
功能富集分析 | 中南大学